Quan Nguyen
cd~ / about / tags / poem / rss /
Tổng hợp vài thứ về Apache Kafka
Tổng hợp từ nhiều nguồn
Kafka là gì?
Kafka là event-streaming platform (distributed message platform),
bên publish dữ liệu được gọi là proceducer còn bên subcribe dữ liệu được gọi là consumer, trong toàn bộ hệ thống,
consumer sẽ nhận dữ liệu theo topic. Kafka có khả năng truyền một lượng message khổng lồ theo thời gian thực (
millions/sec).
Để đảm bảo toàn vẹn dữ liệu trong trường hợp consumer không subcribe được dữ liệu, Kafka sẽ lưu lại các message trên
Queue
và cả trên ổ đĩa đồng thời cũng replicate các message để tránh mất dữ liệu.
Một số đặc trưng của kafka
Distributed
Một distributed system được hiểu đơn giản là chia thành các machine làm việc cùng nhau và trên cùng một cluster dưới dạng một nút cho người dùng cuối. Distributed trong Kafka được hiểu theo nghĩa là lưu trữ, nhận và gửi messages trên các node khác nhau đượi gọi là Broker ( sẽ nói sâu hơn về Broker bên dưới).
Tất nhiên, một Distributed system sẽ đáp ứng được khả năng mở rộng và khả năng chịu lỗi cao.
Horizontal scalable
Như đã nói ở trên, khả năng mở rộng đơn giản chỉ là “ném“ vào nhiều machine hơn, hay trong Kafka là tạo nhiều Broker hơn, trên thực tế việc việc thêm một broker thì không không yêu cầu thời gian chết (downtime)
Fault tolerant
Do Kafka là một Distributed system, nên khả năng chịu lỗi là rất lớn. Ví dụ, một cụm Kafka được thiết kết bởi 5 node, nếu trong trường hợp leader node down thì một trong 4 nốt còn lại sẽ lên thay thế là leader để tiếp tục công việc.
Một điều đáng lưu ý là khảng năng chịu lỗi sẽ được đánh đổi trực tiếp bằng hiệu năng. Một hệ thống có khả năng chịu lỗi thì hiệu suất càng kém.
Commit log
Là một khái niệm cốt lõi của Kafka, Commit log được hình dung là một data structure chỉ cho phép thêm mới record và không thể xóa và sửa đổi record một khi đã được thêm vào commit log. Commit log dựa trên queue data structure tức được sắp xếp từ trái sang phải từ trái sang phải để đảm bảo thứ tự của events.
Kafka lưu trữ data trên local disk, và sắp xếp chúng trong Commit log giúp tận dụng khả năng tìm kiếm tuần tự. Một số lợi ích của cấu trúc Commit log như sau:
- Đọc và ghi trên một không gian không đổi là O(1) do datas được ưu trữ dưới dạng key value.
- Đọc và ghi không ảnh hưởng đến nhau
Lợi ích trên có ưu điểm rất lớn với lượng message scale theo thời gian, ví dụ việc tìm kiếm trên tập 1MB cũng giống như
tìm kiếm trên tập 1GB.

Một số thành phần của Kafka
Broker
Là thành phần cốt lõi của Kafka
Duy trì topic log và leader broker và follower broker cho các partitions được quản lý bởi ZooKeeper
Kafka cluster bao gồm một hoặc nhiều broker
Duy trì việc replicate trên toàn bộ cluster
Producer
Publish message tới một hoặc nhiều topic
Messages được append vào một trong các chủ đề
Được coi là một user trong 1 Kafka cluster
Kafka duy trì thứ tự của Message trên mỗi partition chứ không phải trên toàn partition
Message
Kafka message chứa một mảng các bytes, ngoài ra nó có một metadata tùy chọn được gọi là Key.
Một Message có một Key và được ghi vào một partition cụ thể.
Message cũng được viết đưới dạng các lô, và các lô được nén lại khi truyền qua networking
Chú ý việc ghi dưới dạng các lô sẽ tăng thông lượng nhưng cũng tăng độ trễ, do đó cần cân đối điều này.
Consumer
Subcriber message từ một topic
Một hoặc nhiều Consumer có thể subcrible một topic từ các partition khác nhau, được gọi là consumer group.
2 consumer trong cùng một Group không thể cùng subcribe các messages trong cùng một partition.
Topic
Có thể được xem như một folder của file system
Mỗi message được publish tới topic tại một location cụ thể được gọi là offset. Điều đó có nghĩa là message được xác định là offset number
Mỗi topic, Kafka cluster sẽ duy trì một file log
Dữ liệu trên mỗi phân vùng đều được replicate tời những broker khác để đảm bảo khả năng chịu lỗi
Kafka hoạt động như thế nào?
Record flow
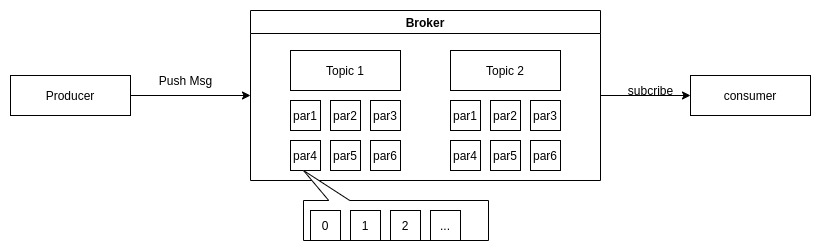
Khi Producer gửi một message lên topic 1 tại partion 4, trường hợp partition trống, message được ghi vào
partitition nhận offset là 0. Tương tự đối với các message tiếp theo, offset sẽ được cập nhật tăng dần đối với mỗi message đầu vào. Kafka đảm bảo rằng tất cả các message sẽ được sắp xếp theo thứ tự do đó khi một consumer subcribe 1 parition cụ thể thì cũng nhận được message theo tuần tự.
Đào sâu hơn về các trường hợp cụ thể của kafka.
Trong trường hợp nhiều producer cùng gửi message vào cùng một topic tại cùng một thời điểm thì kafka xử lý như thế nào?
Kafka xử lý điều này bằng cách tất cả các message có cùng một event key sẽ được ghi vào cùng một partition.
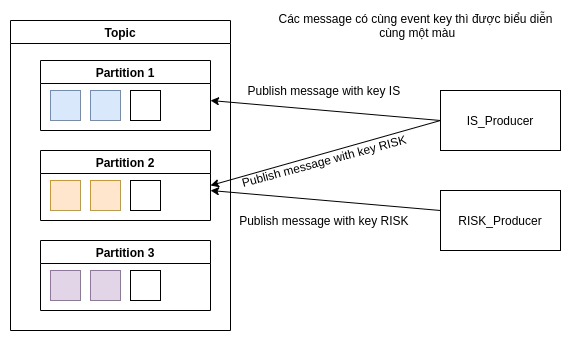
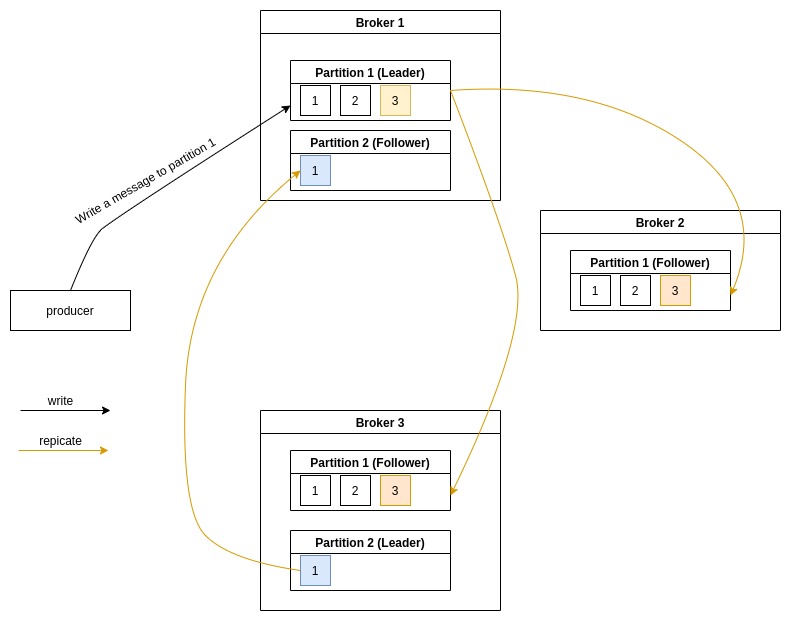
Kafka replication
Dữ liệu trong partitition được sao chép từ N Broker khác nhau để đảm bảo tính toàn vẹn dữ liệu khi một trong các
broker chết.
Lưu ý, trên toàn bộ thời gian xử lý event, thì việc read/write được thực hiện trên partition được gọi là leader. Khi
dữ liệu được ghi vào partition leader, các partition follower từ các broker khác có nhiệm vụ replicates data mới nhận để
đảm bảo an toàn dữ liệu, trên thực tế các parition follower cũng chứa sẵn dữ liệu để sẵn sàng lên làm partition leader
nếu như vì một lý do nào đó mà partition leader dies.
Zookeeper
Khi gửi một message vào Kafka tại một partition cụ thể, Kafka có một khái niệm là ZooKeeper giúp điều hướng message đến đúng partition leader. Đồng thời nếu một leader dies, Zookeeper có nhiệm vụ chọn một follower làm leader để tiếp tục đọc ghi dữ liệu.
Consuming data
Như đã đề cập trước đó, khái niệm Consumer dùng để subcribe data.
Một consumer(không cùng thuộc một group) thì có thể subcribe từ nhiều partition khác nhau.
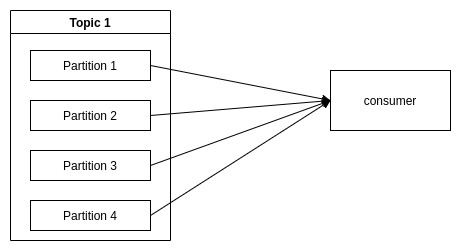
Trường hợp có nhiều consumer cùng thuộc một group, thì nguyên tắc là các consumer trong cùng một group thì không được subcribe cùng một partion trên cùng một topic
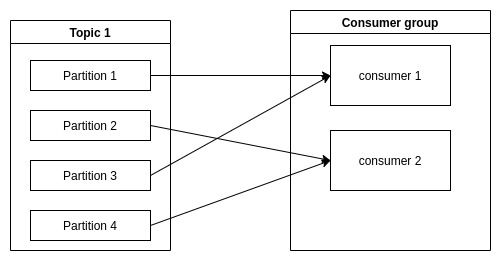
Khi thêm một lượng lớn consumer vựợt quá số lượng partition thì sẽ xảy ra trường hợp consumer không nhận được dữ liệu.
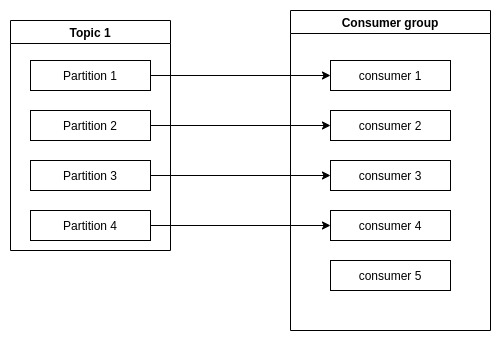
Mỗi Consumer trong một group sẽ chia sẻ Partition cho nhau. Nên khi thêm một consumer mới vào group, consumer mới này sẽ subcribe các message ở các partition được chia sẻ trước đó.
Tại sao Kafka lại nhanh?
- Độ trễ thấp trong việc thao tác file
Việc sử dụng disk thay vì Ram sẽ là giảm tối đa chi phí về hệ thống phần cứng, mặc dùng bất kể thao tác dữ liệu nào
trên Ram đều rất nhanh nhưng nhược điểm là về chi phí, không gian lưu trữ. Để khắc phục điều đó Kafka sử dụng một hệ
thống filesystem và caching.
- Không dùng cấu trúc trees
Thông thường các hệ thống database sử dụng cấu trúc trees để lưu trữ dữ liệu, điều này khiến việc truy suất thông tin
mất O(logN) time. Vì thế đối với hệ thống event streaming thì queue là lựa chọn hợp lý vì tốc độ truy xuất dữ liệu
là O(1)
- Không copy data khi lưu
Vì khi lưu trữ, kafka không tuần tự hóa khi lưu thay vì đó, Kafka lưu các message dưới dạng key-value, đồng thời nội dung message được lưu trong file log dưới dạng binary.
Copyright © 2021- 🚀 Quan Nguyen